

你每天早上过马路,需要同期算明晰对面那辆车的车速、距离和你走完斑马线所需的 3.5 秒吗?
固然不需要。你只会快速看一眼,心里沉默判断一个重要问题:「车会不会撞到我?」然后决定是走如故停。
通盘这个词经过不到一秒,破费的能量聊胜于无。但今天的机器东谈主,真的王人在作念前一种事。
它们被设定为按固定频率来展望宇宙的下一秒,每秒 30 次、50 次,哪怕明知谈接下来的 0.5 秒什么王人没发生,它也必须算完。
这就像你每天早上外出前,王人要圆善野心一遍过马路的 300 个技艺才敢迈出第一步。
累不累?固然累。
重要是,大部分野心王人是空费的。
这即是现时机器东谈主「时灵时不灵」的根柢原因之一:
它们太听话了,听话到对每一帧、每一秒王人平均使劲,从不问我方「什么事值得想,什么事无须想」。
5 月 29 日,自变量机器东谈主推出首个具备「事件级展望才略」的宇宙模子:Wall-WM。
它的中枢即是跳出「如时代均匀采样」的旧范式,模子不再机械地展望每一帧,而是判断哪些顷刻间信得过紧迫。
换句话说,Wall-WM 让机器东谈主终于学会了「捏重心」。
可是,这个宇宙模子的推出,到底意味着什么?
为什么「捏重心」这种东谈主类与生俱来的才略,放到机器东谈主身上就成了底层时代翻新?要回复这些问题,得先从机器东谈主「大脑」的使命花样提及。
1、从机械师法到信得过结实,Wall-WM 是若何作念到的?
目下行业主流的机器东谈主「大脑」叫 VLA(视觉-谈话-算作)。听名字就知谈,一个讲求「看」,一个讲求「听懂东谈主话」,一个讲求「入手」。
听起来挺合理,但问题在于,这三个模块是串联的:视觉模块把看到的东西传给谈话模块,谈话模块结实后再传给算作模块。每传一次,信息就打一次扣头。
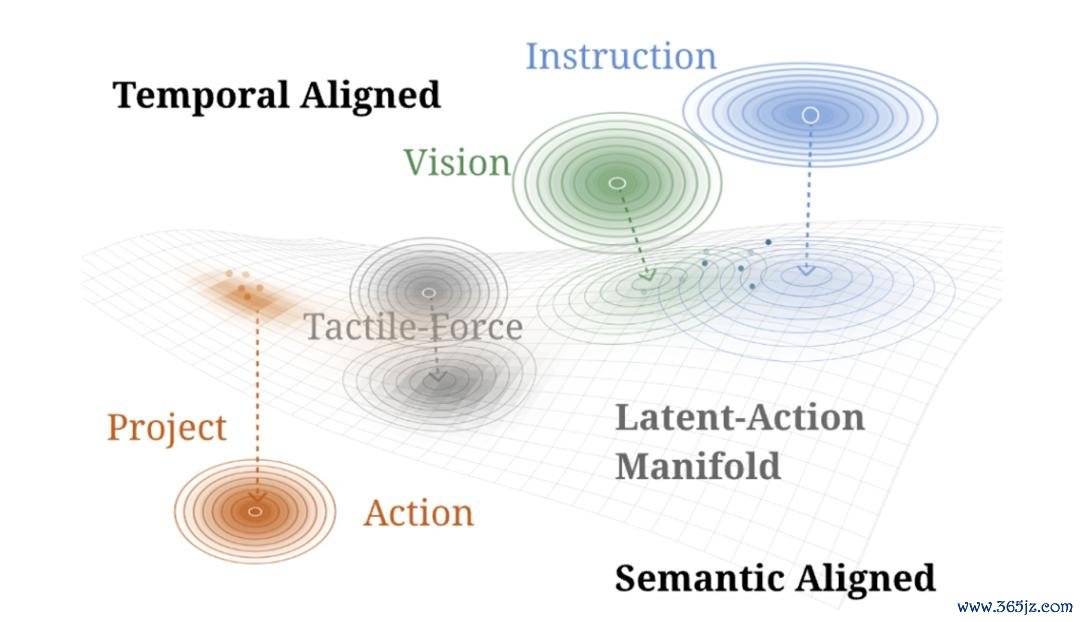
这即是为什么许多机器东谈主看起来很「笨」。不是因为它没看到,而是因为它看到的信息在传到「入手」模块时,如故丢失了一泰半。那有莫得什么办法不错矫正?
自变量机器东谈主给出的谜底是,通过 Wall-WM 这一生界模子,先换掉它想考的时刻单元。
传统模子按固定频率展望畴昔,每秒 30 次、50 次,每一帧王人使劲。哪怕接下来的 0.5 秒什么王人没发生,它也必须算完,这叫「帧级展望」。
但自变量机器东谈主换了一套逻辑:以「事件」为单元来展望。
什么是事件?伸手、捏取、拿起、移动、摈弃,这些在一段时刻内连贯、有明确意旨的算作片断,即是事件。
模子只辞宇宙发生「紧迫变化」时才再行颐养展望。
比如「杯子开动滑落」是一个事件,「手遭遇了杯子」是另一个事件。其他时刻,它不需要每秒想考 30 次。
更紧迫的是,它学到的不是「第 10-20 帧我要执行辅导 X」,而是在此事件下,物理宇宙将若何演化、我应当若何执行。
但这里有一个灭亡的穷苦:
淌若让机器东谈主在学新算作的同期,把底本好结巴易学会的视觉才略给忘掉了,若何办?Wall-WM 在设想上专门磋商了这个「学新不忘旧」的问题。
Wall-WM 的设想很神秘。它的视觉模块和算作模块不是平起平坐的,而是单向耦合:
算作模块只可读取视觉模块的信息,但不可反向干涉它。就像你看书的时候不错记条记,但记条记不会把书上的字改掉。
这么一来,在大限制进修时,模子既能保留原有的视觉结实才略,又能让算作才略不绝增长。工程师也不需要提前「猜」算作该若何编码,因为模子我方会学出来。
但处罚了「学新不忘旧」,Wall-WM 还要处罚另一个老问题:机器东谈主身上有好几个录像头,它若何知谈它们拍到的其实是兼并个东西?
大巨额机器东谈主身上不啻一个录像头,比如头顶一个、左手腕一个、右手腕一个。问题是,它若何知谈这三个录像头拍到的画面是对应兼并个物体的?
传统作念法是让模子我方去学对应关连。
但后果通常不好:模子会偷懒,把跨视角戒备力当成一个通用特征搀杂器,而不是信得夙昔结实空间几何。
因此,Wall-WM 引入了两个机制:
视锥掩码和管状掩码。
视锥掩码从物理层面告诉模子:这两个录像头的画面在空间上根柢不可能对应,别汉典去学它们的关连。
管状掩码则反过来「将就」模子去学那些信得过应该对应的区域,它会成心庇荫一个录像头里的某块区域,逼模子从其他录像头找到沟通的内容。
一个平庸的结实:正常 AI 看东西是「二维拼图」,每一张画面王人是孤独的平面。
而 Wall-WM 看东西是「三维积木」,百家乐2026世界杯中国官方下载它知谈不同角度的画面拼起来是一个立体的物体。哪怕某个角度被庇荫了,它也能「脑补」出物体的真的位置。
看懂空间、结实事件,Wall-WM 在「想什么」上如故比传统模子前进了一大步。但机器东谈主光会想还不够,它还得想得快,毕竟真的宇宙不等东谈主。
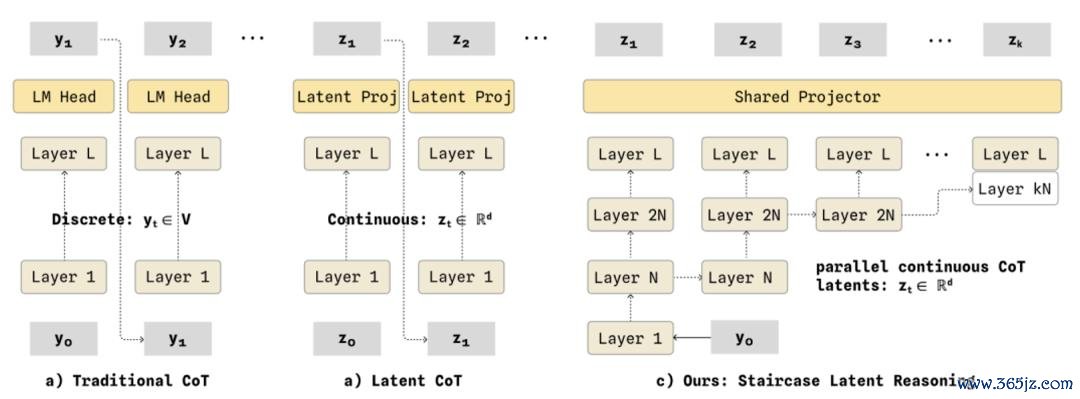
机器东谈主在作念复杂任务时,通常需要「想维链」(CoT),也即是在脑子里先推理一遍再步履。
但传统 CoT 是一步一步推理的,想完第一步,才略想第二步,卓越慢。
米兰体育2026世界杯指定中国官网Wall-WM 的作念法是:
底层只跑一次,高层像道路雷同并行伸开。并且最重要的是,它产出的 CoT 仍然是闹翻可读的文本,你随时不错大开看模子是若何推理的,可阐述性和及时性第一次无须二选一。
2、Wall-WM 的发布,对行业和开垦者来说意味着什么?
从结实事件到看懂空间,再到快速决策,Wall-WM 在底层如故把「机械式」的想考花样改写了一遍。
不外,Wall-WM 还有一个讨巧的设想:兼并套「大脑」,不错纯真适配不同场景。
它有两种模式。一种叫「事件模式」,相宜如故有表层计算器的场景,比如你给机器东谈主一个「把杯子拿过来」的任务,它我方就能拆成伸手、捏取、拿起、移动、摈弃等一串事件,一次输出一个圆善的算作单元,卓越贴合事件领域。
另一种叫「长入模式」,相宜莫得外部计算器、需要端到端及时阻隔的场景。模子我方边推理边执行,保持固定的阻隔频率。
这两种模式不错按需切换,无须再行进修。
轻量级的家庭小机器东谈主不错跑在低算力模式,工业机械臂不错切换到大算力模式。兼并套代码想路,小到扫地机器东谈主,大到工场产线,王人能适配。
关于开垦者来说,再也无须为不同开垦惊羡多套模子,开垦本钱也在大幅裁减。
目下,具身智能行业有一个共鸣正在酿成:
宇宙模子,将成为机器东谈主领域的下一个基础门径,但大巨额王人还停留在论文或者里面系统阶段。
而自变量机器东谈主是把「事件级展望才略」的宇宙模子圆善展示出来的。
它不是放出一个 demo 或者一个 API,而是通逾期代论说戒备公开了整套想路、模子设想、进修决策和实验数据。
而实验收尾,也考证了「事件级展望」这条路线的有用性。
在真机 Core15 L1 基准测试中,Wall-WM 的平均任务完因素数明显越过 π0.5 与 DreamZero 等同类模子。
在基础任务、推理任务、智慧操作以及泛化场景下,均展现出了更强的完成才略,亦然目下轮廓辅导设定下完成度最高的 L1 模子之一。
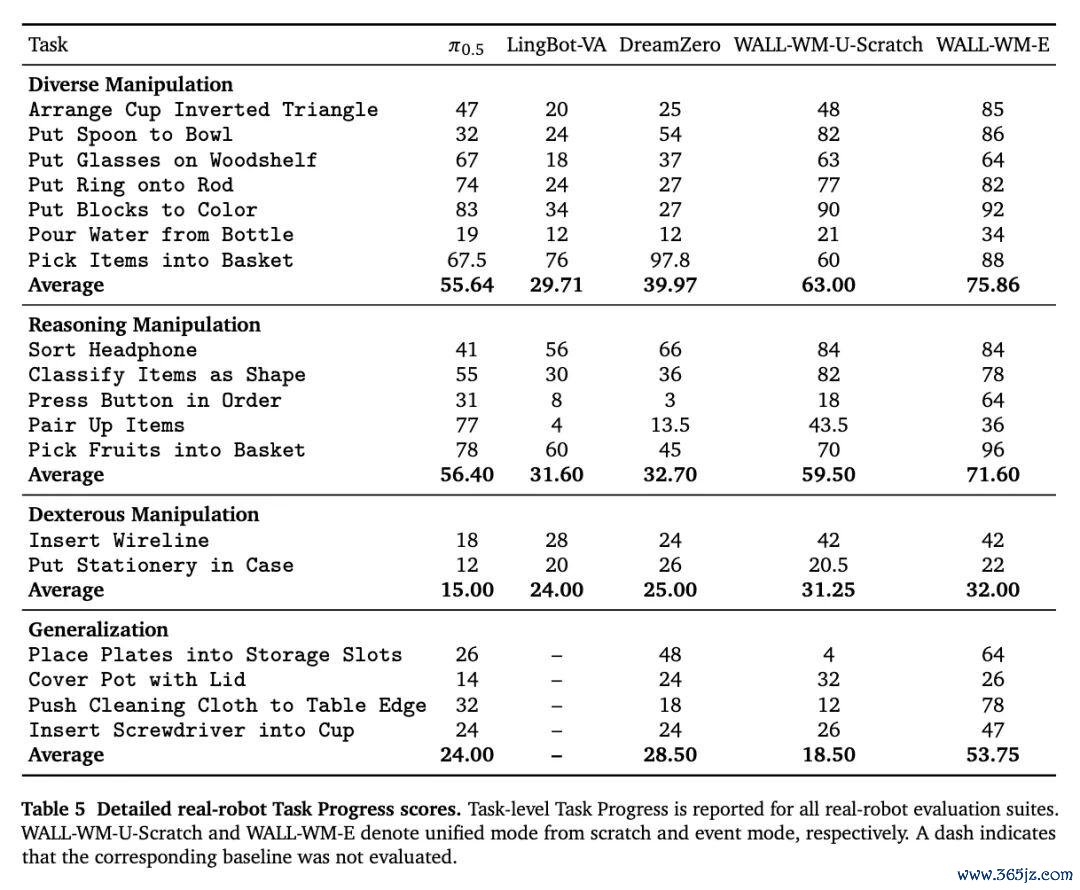
这意味着,Wall-WM 提高的如故不仅仅机械执行才略,而是机器东谈主关于复杂任务与轮廓标的的结实才略。
与此同期,在具身视频生成(Embodied Video Generation)测试中,比较 Wan2.1、Wan2.2 等传统视频生成模子,Wall-WM 在 Motion Quality(算作质料)、Semantic Consistency(语义一致性)以及 Physical Plausibility(物理合感性)等多个具身有关维度上,均罢了了明显越过。

这背后,骨子上即是因为它不再仅仅逐帧生成画面,而是在展望「事件」如安在真的物理宇宙中演化。
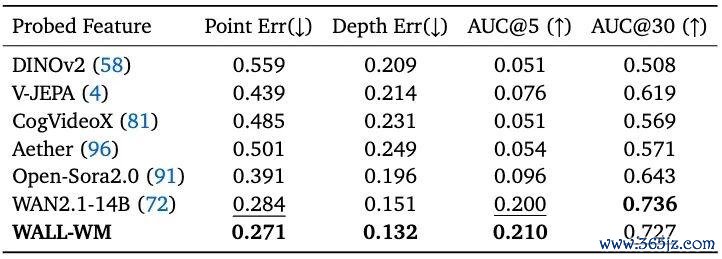
此外,在 3D Awareness(CO3Dv2)测试中,Wall-WM 在 Point Error 与 Depth Error 两项空间罪责方针上,也优于 WAN2.1-14B、Open-Sora 2.0、V-JEPA、DINOv2 等模子。
但比较性能提高,更紧迫的是,它转变了机器东谈主结实宇宙的花样。
夙昔的机器东谈主,对每一帧王人在使劲;而当今,它开动学会像东谈主雷同,知谈什么值得想考,什么不值得损失算力。
而 Wall-WM 信得过的价值,或者并不在于它是又一个跑分更高的 VLA 模子,而在于它把如安在保留多模态视觉先验与空间几何结实的同期,让模子信得过学会展望物理宇宙这个具身基础模子的根柢问题,给出了一套自洽的工程化谜底。
在这里百家乐正规平台2026最新版下载,「事件」不再仅仅一个算作标注粒度,而开动成为宇宙模子信得过的想考单元。
